أعلنت Amazon Bedrock عن إمكانيات جديدة للتقييم في RAG و LLM-as-a-judge، مما يبسط اختبار تطبيقات الذكاء الاصطناعي التوليدي. تتضمن قاعدة معارف Amazon Bedrock الآن إمكانية تقييم RAG، مما يتيح لك إجراء تقييم تلقائي لقاعدة المعارف لتحسين تطبيقات RAG. تستخدم عملية التقييم نموذج لغة كبير (LLM) لحساب المقاييس. يتيح لك ذلك مقارنة التكوينات المختلفة وضبط الإعدادات للحصول على النتائج المطلوبة لحالة الاستخدام الخاصة بك. يتضمن تقييم نموذج Amazon Bedrock الآن LLM-as-a-judge، مما يتيح لك إجراء الاختبارات وتقييم النماذج الأخرى بجودة شبيهة بالبشر بتكلفة وجزء من الوقت اللازم لإجراء التقييمات البشرية. توفر هذه الإمكانيات الجديدة تقييمًا سريعًا وتلقائيًا لتطبيقات الذكاء الاصطناعي، مما يقصر حلقات التغذية الراجعة ويسرع التحسينات. تقوم هذه التقييمات بتقييم أبعاد جودة متعددة، بما في ذلك الصحة والفائدة ومعايير الذكاء الاصطناعي المسؤولة مثل رفض الإجابة والضرر. لتسهيل الأمر وجعله بديهيًا، توفر نتائج التقييم تفسيرات باللغة الطبيعية لكل درجة في المخرجات وعلى وحدة التحكم، ويتم تطبيع الدرجات من 0 إلى 1 لسهولة التفسير. يتم نشر القواعد بالكامل مع مطالبات القاضي في الوثائق حتى يتمكن غير العلماء من فهم كيفية اشتقاق الدرجات.
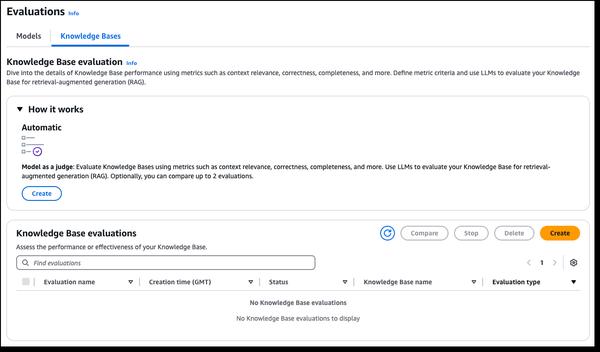
إمكانيات جديدة لتقييم RAG و LLM-as-a-judge في Amazon Bedrock
AWS